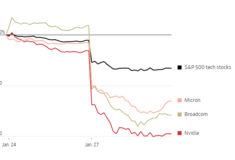
Η κινεζική εταιρεία δημιουργίας τεχνητής νοημοσύνης (AI) DeepSeek υιοθέτησε καινοτόμες τεχνικές για την ανάπτυξη ενός μοντέλου που εκπαιδεύτηκε με περιορισμένη ανθρώπινη παρέμβαση, ωθώντας σε μια ερίγδουπη εμφάνιση, που προκάλεσε πανικό στις αγορές και θα μπορούσε να μετασχηματίσει το κόστος που απαιτείται ώστε οι προγραμματιστές να δημιουργήσουν εφαρμογές με βάση την τεχνολογία.
Το έγγραφο που δημοσιεύθηκε σχετικά με τη λειτουργία του μοντέλου «συλλογιστικής» R1 της DeepSeek αποκαλύπτει πώς η ομάδα, με επικεφαλής τον δισεκατομμυριούχο του hedge fund Λιάνγκ Γουένφενγκ, πέτυχε σε μεγάλο βαθμό να εξαλείψει πολλά εμπόδια στην ανάπτυξη της τεχνητής νοημοσύνης. Το έγγραφο δείχνει πώς η DeepSeek υιοθέτησε μια σειρά από πιο αποτελεσματικές τεχνικές για την ανάπτυξη του R1, το οποίο, όπως και το αντίπαλο μοντέλο o1 της OpenAI, παράγει ακριβείς απαντήσεις «σκεπτόμενο» βήμα προς βήμα τις απαντήσεις του για μεγαλύτερο χρονικό διάστημα από ό,τι τα περισσότερα μεγάλα γλωσσικά μοντέλα.
Τα επιτεύγματα της DeepSeek προέρχονται από τη χρήση της «μάθησης μέσω ενίσχυσης» (RL) για τη μείωση της ανθρώπινης συμμετοχής στην παραγωγή απαντήσεων σε προτροπές. Η εταιρεία έχει επίσης δημιουργήσει μικρότερα μοντέλα με λιγότερες παραμέτρους - τον αριθμό των μεταβλητών που χρησιμοποιούνται για την εκπαίδευση ενός συστήματος τεχνητής νοημοσύνης και τη διαμόρφωση της παραγωγής του - με ισχυρές ικανότητες συλλογισμού, βελτιώνοντας μεγάλα μοντέλα που εκπαιδεύονται από ανταγωνιστές όπως η Meta και η Alibaba. Μαζί, αυτές οι εξελίξεις έχουν προκαλέσει σοκ σε όλη τη Silicon Valley, καθώς το R1 υπερτερεί σε ορισμένες εργασίες σε σύγκριση με τα μοντέλα που κυκλοφόρησαν πρόσφατα από την OpenAI, την Anthropic και τη Meta, αλλά με ένα κλάσμα των χρημάτων για την ανάπτυξή τους.
«Νομίζω ότι είναι μόνο η κορυφή του παγόβουνου όσον αφορά το είδος της καινοτομίας που μπορούμε να περιμένουμε σε αυτά τα μοντέλα», δήλωσε ο Neil Lawrence, καθηγητής μηχανικής μάθησης της DeepMind στο πανεπιστήμιο του Cambridge. «Η ιστορία δείχνει ότι οι μεγάλες επιχειρήσεις δυσκολεύονται να καινοτομήσουν καθώς κλιμακώνονται, και αυτό που έχουμε δει από πολλές από αυτές τις μεγάλες επιχειρήσεις είναι η αντικατάσταση της πνευματικής σκληρής δουλειάς από επενδύσεις σε υπολογιστές».
Τα σταδιακά βήματα και η εμφατική παρουσίαση
Τα μεγάλα γλωσσικά μοντέλα κατασκευάζονται σε δύο στάδια. Το πρώτο ονομάζεται «προ-εκπαίδευση», κατά το οποίο οι προγραμματιστές χρησιμοποιούν τεράστια σύνολα δεδομένων που βοηθούν τα μοντέλα να προβλέψουν την επόμενη λέξη σε μια πρόταση. Το δεύτερο στάδιο ονομάζεται «μετεκπαίδευση», μέσω της οποίας οι προγραμματιστές μαθαίνουν στο μοντέλο να ακολουθεί οδηγίες, όπως η επίλυση μαθηματικών προβλημάτων ή η κωδικοποίηση. Ένας τρόπος για να κάνουν τα chatbots να παράγουν πιο χρήσιμες απαντήσεις ονομάζεται «μάθηση μέσω ενίσχυσης από ανθρώπινη ανατροφοδότηση» (RLHF), μια τεχνική που εφαρμόστηκε από την OpenAI για τη βελτίωση του ChatGPT. Η RLHF λειτουργεί με ανθρώπινους σχολιαστές που επισημαίνουν τις απαντήσεις του μοντέλου τεχνητής νοημοσύνης σε προτροπές και επιλέγουν τις απαντήσεις που είναι καλύτερες. Αυτό το βήμα είναι συχνά επίπονο, ακριβό και χρονοβόρο, απαιτώντας συχνά έναν μικρό στρατό ανθρώπινων μαρκαδόρων δεδομένων. Η μεγάλη καινοτομία της DeepSeek είναι η αυτοματοποίηση αυτού του τελικού βήματος, χρησιμοποιώντας μια τεχνική που ονομάζεται ενισχυτική μάθηση (RL), κατά την οποία το μοντέλο ΤΝ ανταμείβεται επειδή κάνει το σωστό.
Η DeepSeek ανέπτυξε πρώτα ένα ισχυρό μοντέλο πρόβλεψης κειμένου που ονομάζεται V3. Στη συνέχεια χρησιμοποίησε RL για να «ανταμείψει» το μοντέλο, όπως για παράδειγμα να του δώσει ένα μπράβο για την παραγωγή της σωστής απάντησης. Η κινεζική εταιρεία διαπίστωσε ότι κάνοντας αυτή τη διαδικασία αρκετές φορές, το μοντέλο κατάφερε να λύσει αυθόρμητα προβλήματα χωρίς ανθρώπινη επίβλεψη. Αυτή η τεχνική χρησιμοποιήθηκε επίσης από την Google DeepMind για την κατασκευή του AlphaGo, του συστήματος τεχνητής νοημοσύνης που νίκησε τους ανθρώπινους παίκτες στο αρχαίο επιτραπέζιο παιχνίδι Go και έδωσε το έναυσμα για τη σημερινή έκρηξη των υπολογιστικών τεχνικών βαθιάς μάθησης πριν από σχεδόν μια δεκαετία. Η DeepSeek δήλωσε «εύρηκα» όταν επαναξιολόγησε τις απαντήσεις του και προσάρμοσε τον χρόνο επεξεργασίας του για την επίλυση διαφορετικών ερωτήσεων. «Η στιγμή που αναφωνήσαμε 'εύρηκα' χρησιμεύει ως μια έντονη υπενθύμιση των δυνατοτήτων της [RL] να ξεκλειδώσει νέα επίπεδα νοημοσύνης στα συστήματα τεχνητής νοημοσύνης, ανοίγοντας τον δρόμο για πιο αυτόνομα και ευπροσάρμοστα μοντέλα στο μέλλον», έγραψαν οι δημιουργοί της DeepSeek στο έγγραφο.
Ο Lewis Tunstall, ερευνητής στη Hugging Face, μια εταιρεία ερευνών τεχνητής νοημοσύνης, δήλωσε: «Φαίνεται ότι η μυστική σάλτσα για να δουλέψει αυτό είναι να έχεις ένα πολύ, πολύ ισχυρό προ-εκπαιδευμένο μοντέλο και στη συνέχεια να έχεις πολύ, πολύ καλή υποδομή για να κάνεις αυτή τη διαδικασία ενισχυτικής μάθησης σε μεγάλη κλίμακα».
Μικρά μοντέλα που κατασκευάζονται χρησιμοποιώντας μεγάλα
Ενώ η OpenAI και η Google επενδύουν δισεκατομμύρια δολάρια για την κατασκευή μεγάλων γλωσσικών μοντέλων, η DeepSeek έχει επίσης κατασκευάσει μικρότερα μοντέλα που μπορούν να εκτελούνται σε τηλέφωνα ή προγράμματα περιήγησης στο διαδίκτυο, "αποστάζοντας" τις δυνατότητες συλλογισμού των μεγαλύτερων μοντέλων.
Η DeepSeek χρησιμοποίησε το μοντέλο R1 για να δημιουργήσει ένα σχετικά μικρό σύνολο 800.000 σημείων δεδομένων και στη συνέχεια βελτίωσε τα μοντέλα που κατασκευάστηκαν από ανταγωνιστές όπως το Qwen της Alibaba και το Llama της Meta χρησιμοποιώντας αυτά τα δεδομένα που δημιούργησε η τεχνητή νοημοσύνη. Η DeepSeek διαπίστωσε ότι αυτά τα αποσταγμένα μοντέλα ήταν ιδιαίτερα ισχυρά σε συγκριτικά κριτήρια συλλογισμού, σε ορισμένες περιπτώσεις ξεπερνώντας μοντέλα-ναυαρχίδες όπως το Claude της Anthropic. "Βασικά μπορεί να λύσει τα περισσότερα από τα μαθηματικά προβλήματα που έκανα στις προπτυχιακές σπουδές μου", δήλωσε ο Tunstall.
Αυτή η εξέλιξη θα μπορούσε να είναι μια ευλογία για τους προγραμματιστές εφαρμογών, οι οποίοι έχουν έναν φθηνό και αποτελεσματικό τρόπο να κατασκευάζουν προϊόντα. Η διδασκαλία των μοντέλων τεχνητής νοημοσύνης να συλλογίζονται κατά τη διάρκεια της «συμπερασματολογίας» - όταν το μοντέλο παράγει απαντήσεις - είναι πολύ πιο αποτελεσματική από τη διαδικασία προ-εκπαίδευσης, η οποία απαιτεί μεγάλη υπολογιστική ισχύ, σύμφωνα με τον Lennart Heim, ερευνητή στη Rand, μια δεξαμενή σκέψης.
Αυτό το νέο παράδειγμα θα μπορούσε να επιτρέψει στους ανταγωνιστές να κατασκευάσουν ανταγωνιστικά μοντέλα με πολύ λιγότερη υπολογιστική ισχύ και χρήματα, πρόσθεσε. Ωστόσο, χωρίς χρήματα για τσιπ, "απλά δεν μπορούν να τα αναπτύξουν στην ίδια κλίμακα", δήλωσε ο Heim.Η DeepSeek δεν δήλωσε πόσα δαπάνησε για την κατασκευή του R1, αλλά ισχυρίστηκε ότι εκπαίδευσε το μοντέλο V3, στο οποίο βασίζεται το R1, με μόλις 5,6 εκατ. δολάρια. Το ποσό αυτό δεν περιλαμβάνει άλλα κόστη, όπως η πιθανή απόκτηση χιλιάδων μονάδων επεξεργασίας γραφικών για την εκπαίδευση του μοντέλου, ούτε μισθούς, πειράματα, εκπαίδευση και ανάπτυξη, δήλωσε ο Heim.
Και ενώ η DeepSeek ήταν η πρώτη που χρησιμοποίησε τις συγκεκριμένες τεχνικές της, άλλα εργαστήρια τεχνητής νοημοσύνης αναμένεται να ακολουθήσουν το παράδειγμά της, με τη Hugging Face να εργάζεται ήδη για την αντιγραφή της R1. Οι αμερικανικές εταιρείες τεχνητής νοημοσύνης έχουν επίσης εργαστεί για τη χρήση των δυνατοτήτων των μεγάλων, υπερσύγχρονων μοντέλων τους σε μικρότερα, πιο ευέλικτα μοντέλα. Η Google λάνσαρε πέρυσι το Gemma, το οποίο είναι ένα πιο ελαφρύ μοντέλο βασισμένο στο δικό της Gemini.«Η συνταγή της νοημοσύνης είναι αρκετά απλή», λέει ο Thomas Wolf, συνιδρυτής και επιστημονικός υπεύθυνος της Hugging Face, προσθέτοντας ότι οι τεχνικές της DeepSeek ήταν καλά κατανοητές από άλλους στον τομέα. «Και γι' αυτό περιμένω ότι πολλές ομάδες μπορούν να το ξανακάνουν αυτό».
Με πληροφορίες από Financial Times